提示词工程-反思模式
什么是 Reflexion?
Reflexion 是一种先进的 AI Agent 架构,其核心思想是让 Agent 具备自我反思和自我修正的能力。它不仅仅是简单地执行任务(像传统的 ReAct – Reason and Act 模式),而是在遇到失败或障碍时,能够停下来“复盘”自己的行为轨迹,从中吸取教训,并形成指导性的“经验”,用于下一次的尝试。
简单来说,Reflexion 赋予了 Agent 一种从失败中学习的机制,模拟了人类在解决复杂问题时的试错和总结过程。
这项技术主要源于康奈尔大学等机构在 2023 年发表的论文《Reflexion: Language Agents with Verbal Reinforcement Learning》。
Reflexion 与传统方法的区别
| 特性 | 传统 ReAct Agent | Reflexion Agent |
|---|---|---|
| 核心循环 | 思考 -> 行动 -> 观察 (Thought -> Act -> Observation) | 尝试 -> 评估 -> 反思 -> 再次尝试 (Trial -> Evaluate -> Reflect -> Retry) |
| 失败处理 | 可能会在当前步骤卡住,或进行无效的重复尝试。 | 将整个失败的“轨迹”作为学习材料,进行深入分析。 |
| 记忆 | 通常是短期的“暂存器”(Scratchpad),记录当前任务的步骤。 | 拥有一个长期、不断累积的“反思记忆库”(Reflexion Memory)。 |
| 学习方式 | 主要依赖于 In-context Learning,受限于单次提示的长度和内容。 | 通过“语言强化学习”,将反思(Verbal Feedback)作为内部奖励信号来指导后续行为。 |
Reflexion 的核心组件
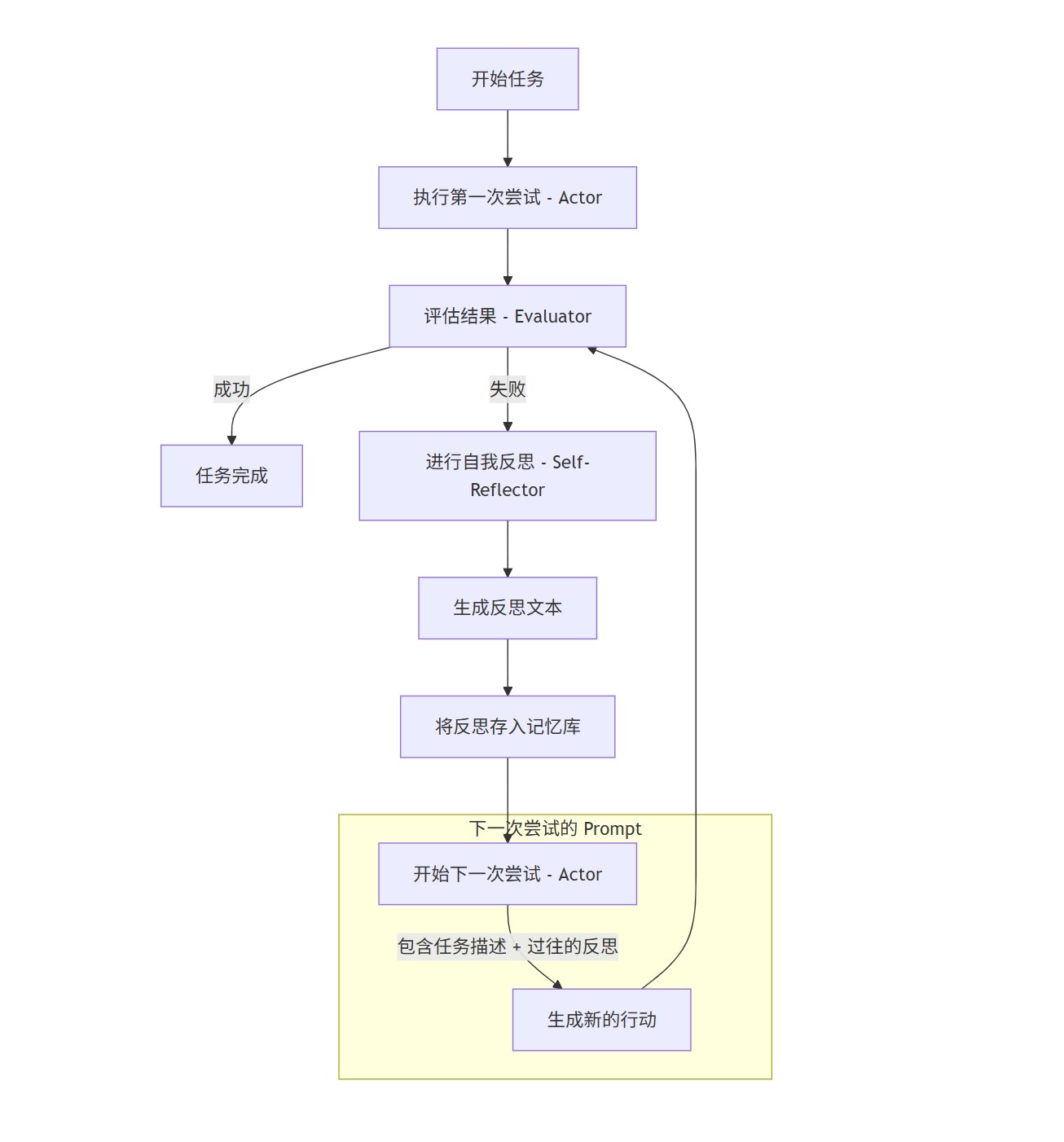
一个完整的 Reflexion 流程包含三个关键角色,它们都可以由同一个大型语言模型(LLM)通过不同的 Prompt 来扮演:
行动者 (Actor):
- 职责: 根据任务目标和当前的“反思记忆”,生成思考和具体行动指令。
- 工作方式: 这是 Agent 的“手和脚”,负责与外部环境(如代码解释器、搜索引擎)交互。在后续的尝试中,Actor 的 Prompt 会包含之前失败后总结的反思,从而避免重蹈覆辙。
评估者 (Evaluator):
- 职责: 判断行动者的输出结果是成功、失败还是部分成功。
- 工作方式: 评估者检查 Actor 的行动轨迹(Trajectory)和最终结果。评估可以是简单的基于规则的检查(例如,代码是否成功运行),也可以是复杂的、基于 LLM 的语义判断(例如,生成的文章是否回答了问题)。
自我反思者 (Self-Reflector):
- 职责: 这是 Reflexion 的核心。当评估者给出“失败”信号时,反思者被激活。它会分析整个失败的行动轨迹,并生成一段简洁、高度概括、具有指导意义的反思文本 (Reflection Text)。
- 工作方式: 反思者会被要求回答“为什么之前的尝试会失败?”以及“下一次应该如何做才能避免这个错误?”。生成的反思文本会被存储到“反思记忆库”中。
工作流程图
下面是 Reflexion Agent 的典型工作流程:
如何使用 Reflexion Prompt 开发 Agent
开发一个 Reflexion Agent 的本质,就是设计一套精巧的 Prompt 链,来分别驱动 Actor, Evaluator 和 Reflector 这三个角色,并管理好“反思记忆库”。
第1步:定义 Agent 的核心组件
你需要准备三个主要的 LLM 调用函数,或者说三个核心 Prompt。
1. Actor Prompt (行动者提示)
这是 Agent 执行任务的基础。与 ReAct 不同的是,你需要为它注入“反思记忆”。
基础结构:
你是一个{Agent角色,如AI程序员}。你需要解决以下任务。 # 任务 {task_description} # 思考过程 你需要一步步思考,然后选择一个工具/行动。可用的工具有: {tool_list}。 # 反思 (如果记忆库不为空) 在之前的尝试中,你犯了一些错误。请参考以下从失败中总结的经验教训,避免重蹈覆覆: {reflection_memory} # 行动轨迹 (Scratchpad) {scratchpad}{reflection_memory}: 这是一个变量,用于动态插入所有过去的反思文本。在第一次尝试时,这里是空的。{scratchpad}: 用于记录当前尝试中的“Thought, Action, Observation”序列。
2. Evaluator Prompt (评估者提示)
评估可以是简单的代码检查,也可以是复杂的 LLM 判断。对于需要语义理解的评估,可以使用如下 Prompt:
基础结构:
# 角色 你是一个严谨的评估机器人。 # 原始任务 {task_description} # Agent 的行动轨迹 {agent_trajectory} # 评估标准 请根据以下标准判断 Agent 是否成功完成了任务: 1. {criterion_1} 2. {criterion_2} # 你的判断 请严格回答 "Success" 或 "Failure"。{agent_trajectory}: 传入 Actor 在一次完整尝试中的所有记录。
3. Self-Reflector Prompt (自我反思提示)
这是整个 Reflexion 机制的灵魂。当 Evaluator 返回 "Failure" 时,调用此 Prompt。
基础结构:
# 角色 你是一个善于反思和总结的 AI 导师。 # 失败的尝试 一个 Agent 在尝试解决以下任务时失败了。 任务: {task_description} 这是它失败的完整行动轨迹: {failed_trajectory} # 你的任务 请仔细分析上述轨迹,找出导致失败的关键原因。然后,生成一条或几条简洁、通用、具有指导意义的反思。这条反思应该像一个警句或策略,帮助 Agent 在未来的尝试中避免同样的错误。 # 输出要求 - 直接输出反思文本。 - 语言要精炼,不超过 50 个字。 - 专注于策略层面,而不是具体的代码细节。 # 你的反思:- 示例输出 (反思文本):
- "如果一个库的某个函数不存在,应该先检查库的版本或者查阅官方文档,而不是猜测函数名。"
- "在进行文件写入前,必须先确认目标目录是否存在,如果不存在则需要创建它。"
- "当网页爬取不到预期内容时,应检查请求头(Headers)是否模拟了真实浏览器,以防被屏蔽。"
第2步:搭建 Agent 的主循环
有了这三个核心 Prompt,你就可以编写 Agent 的主控制逻辑了。
伪代码示例:
def run_reflexion_agent(task, max_trials=3):
# 初始化反思记忆库
reflection_memory = []
for i in range(max_trials):
print(f"--- 开始第 {i+1} 次尝试 ---")
# 1. 执行一次完整的尝试 (Actor)
# Actor 的 prompt 中会包含 reflection_memory
current_trajectory = execute_trial(task, reflection_memory)
# 2. 评估结果 (Evaluator)
is_successful = evaluate_trial(task, current_trajectory)
if is_successful:
print("任务成功!")
return current_trajectory
else:
print("尝试失败,开始反思...")
# 3. 如果失败,进行反思 (Self-Reflector)
new_reflection = generate_reflection(current_trajectory)
print(f"新的反思: {new_reflection}")
# 4. 更新记忆库
reflection_memory.append(new_reflection)
print("已达到最大尝试次数,任务失败。")
return None
# --- Helper Functions ---
def execute_trial(task, reflections):
# 调用 LLM (Actor Prompt) 来生成一系列的 thought-action-observation
# ... 实现细节 ...
return trajectory
def evaluate_trial(task, trajectory):
# 调用 LLM (Evaluator Prompt) 或其他规则来判断成功与否
# ... 实现细节 ...
return True_or_False
def generate_reflection(failed_trajectory):
# 调用 LLM (Self-Reflector Prompt) 来生成反思文本
# ... 实现细节 ...
return reflection_text关键的实现细节与建议
管理记忆库和上下文窗口: 反思记忆会不断增长。如果记忆过多,可能会超出 LLM 的上下文窗口限制。你需要策略来管理它,例如:
- 只保留最近的 N 条反思。
- 对所有反思进行一次更高层次的总结。
- 使用向量数据库,根据当前失败情境检索最相关的反思。
反思的质量至关重要: Self-Reflector Prompt 的设计直接决定了 Agent 的学习效率。一个好的反思应该是通用且可操作的,而不是简单地复述错误。
分层反思 (Hierarchical Reflection): 对于非常复杂的任务,可以设计两层反思。第一层针对短期策略,第二层在多次失败后进行更高层次、更长远的战略总结。
总结
Reflexion 是一种强大但实现起来也更复杂的 Agent 架构。它通过将失败转化为学习机会,极大地提升了 Agent 在需要多步推理、试错和规划的复杂任务上的鲁棒性和成功率。
要成功开发一个 Reflexion Agent,关键在于设计出能够精准驱动 Actor、Evaluator 和 Self-Reflector 这三大核心角色的 Prompt,并实现一个有效的主循环来调度它们和管理反思记忆。这不仅仅是技术实现,更是一门 Prompt Engineering 的艺术。