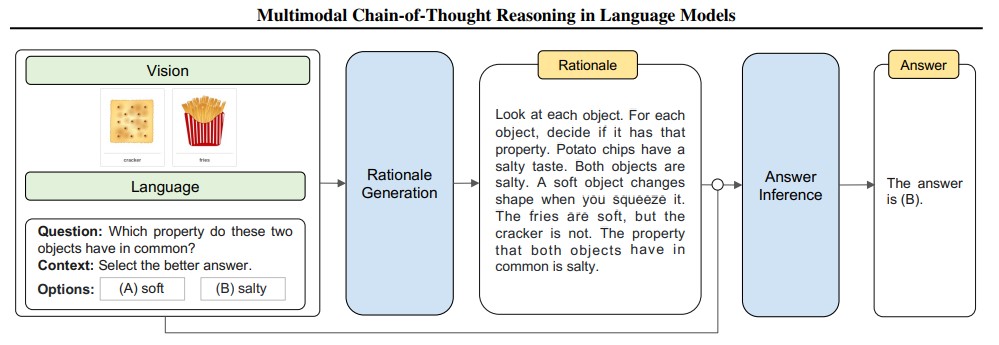
如何使用DeepSeek的API开发大模型应用
DeepSeek-v3 和 DeepSeek-r1
最近Deepseek因为连续发布了Deepseek-v3和Deepseek-r1两个模型而迅速出圈,在全球科技领域引起了很大的轰动。
Deepseek2024年12月底发布并开源了DeepSeek-V3模型,性能可比肩顶级闭源模型。
Deepseek2025年1月发布了推理模型DeepSeek-R1,在多项测试中超越了OpenAI的o1模型。
以下是它们的基本介绍:
DeepSeek-V3
DeepSeek-V3 是一种混合专家(MoE)模型,具有 6710 亿参数,同时激活 370 亿参数。它在知识基础任务、长文本处理、代码生成和数学推理方面表现出色。它在中文语言能力方面也颇具特色。DeepSeek-V3 结合了多头潜在注意力(MLA)、DeepSeekMoE 和多标记预测(MTP)等创新。
主要特性和亮点:
- 性能:DeepSeek V3 在一些领域超越了其他开源模型,并在某些方面与顶尖闭源模型如 GPT-4o 和 Claude 竞争。它在 MMLU(EM)上达到了 88.5% 的准确率,在 MMLU-Redux(EM)上达到了 89.1% 的准确率。
- 速度:其生成速度提高了三倍,从每秒 20 个标记增加到 60 个标记(TPS)。
- 架构:DeepSeek-V3 采用了一种新的负载平衡策略,不依赖于辅助损失。它使用细粒度专家系统,动态调整专家路由,以确保负载平衡而不牺牲模型性能。
- 训练:DeepSeek-V3 使用 FP8 混合精度训练框架,完成了对 14.8 万亿标记的预训练,使用了 2.664M H800 GPU 小时。它从 DeepSeek R1 等模型中提炼推理能力,以提高其推理性能。
DeepSeek R1
DeepSeek R1 是一个基于开源和强化学习(RL)的模型,以其推理能力而闻名。它几乎完全依赖于 RL 进行微调,最小化了对标记数据集的需求。
主要特性和亮点:
- 推理:DeepSeek R1 在数学、代码和自然语言任务中表现出强大的推理能力。在 AIME 2024 数学竞赛中,它达到了 79.8% 的 pass@1 得分。在 Codeforces 上获得了 2029 Elo 评分,超过了 96.3% 的人类参与者。
- 训练:DeepSeek R1 使用多阶段训练过程,在强化学习之前集成冷启动数据。它采用基于规则的方法,确保可扩展的强化学习,并将强大的推理能力推广到其他领域。
- 性价比:与 OpenAI 的 o1 模型相比,DeepSeek R1 的训练成本更低。每百万个标记的输入成本便宜 90%,输出价格约低 27 倍。
- 开源:DeepSeek R1 在 MIT 许可下开源,允许用户自由使用、修改、分发和商业化该模型。
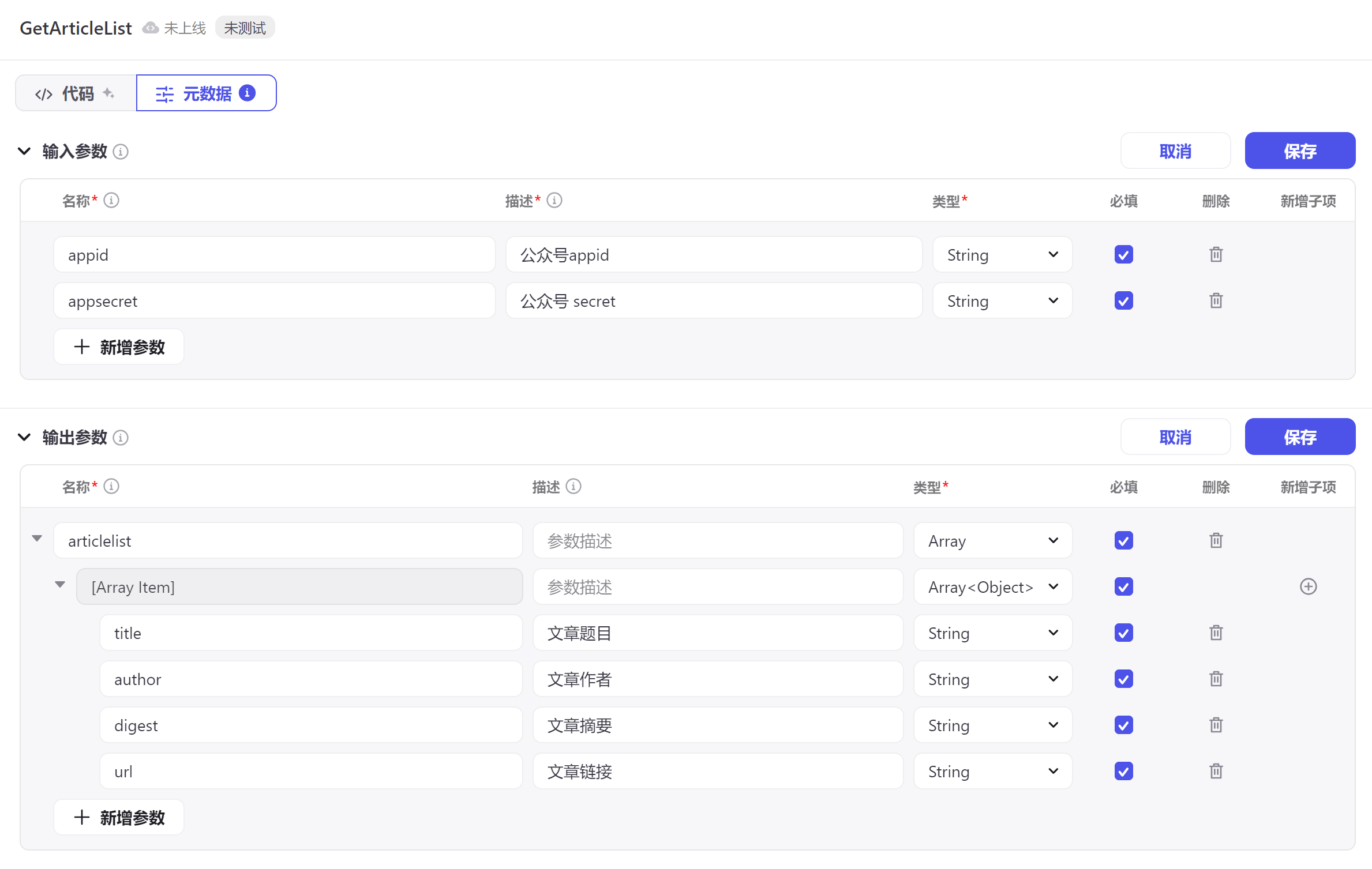
申请DeepSeek的API Key
进入DeepSeek官网, 点击右上角的“API开放平台”按钮,进入API开放平台页面。
选择“API Key”,点击“创建API Key”按钮,创建一个API Key。将你的API Key保存到安全的地方,后续会用到。
使用API Key调用DeepSeek的API
使用curl调用DeepSeek的API
curl https://api.deepseek.com/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer " \
-d '{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"stream": false
}' 使用Python调用DeepSeek的API
DeepSeek的API与OpenAI的API兼容,因此完全可以使用OpenAI的SDK直接调用DeepSeek的API。
这也是官方文档推荐的方法。
# Please install OpenAI SDK first: pip3 install openai
from openai import OpenAI
client = OpenAI(api_key="", base_url="https://api.deepseek.com")
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "Hello"},
],
stream=False
)
print(response.choices[0].message.content)
使用Langchain封装的接口调用DeepSeek的API
使用OpenAI的库是相对简单和直接的方法,但是OpenAI的库功能相对单一,如果需要更复杂
的功能,比如链式调用、内存管理、工具调用等,还是需要使用LangChain。
LangChain介绍
LangChain 是一个用于开发由大型语言模型(LLMs)驱动的应用程序的框架。简化了 LLM
应用程序生命周期的每个阶段,提供了一套工具、组件和接口,帮助开发者更高效地构建智
能应用。 LangChain 的主要功能包括:
- 模型输入/输出(Model I/O):理大型语言模型的输入(Prompts)和输出格式化
(Output Parsers)。 - 数据连接(Data Connection):理向量数据存储(Vector Stores)、内容数据获取
(Document Loaders)和转换(Transformers),以及向量数据查询(Retrievers)。 - 记忆(Memory):于存储和获取对话历史记录的功能模块。
- 链(Chains): Memory、Model I/O 和 Data Connection 串联起来,实现连续对话
和推理流程。 - 代理(Agents):于 Chains 进一步集成工具(Tools),将大语言模型的能力与本
地或云服务结合。 - 回调(Callbacks):供回调系统,可连接到 LLM 应用的各个阶段,便于日志记录和
追踪。过这些功能,开发者可以创建各种应用程序,包括聊天机器人、智能问答工具、文档
摘要生成等。
LangChain 还支持与外部数据源的连接,使语言模型能够与其环境进行交互,增强应用程序
的功能和灵活性。2022 年 10 月推出以来,LangChain 迅速获得了开发者的关注和支持,
成为构建 LLM 驱动应用程序的强大工具。
使用LangChain Python调用DeepSeek的API
# 安装必要库(如果未安装)
# pip install langchain-core langchain-openai
import os
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
# 设置环境变量(替换为您的API Key)
os.environ["DEEPSEEK_API_KEY"] = "sk-your-api-key-here"
# 创建 DeepSeek 模型实例
# 假设 DeepSeek API 兼容 OpenAI 格式
model = ChatOpenAI(
model="deepseek-chat", # 指定模型名称
base_url="https://api.deepseek.com/v1", # DeepSeek API 地址
api_key=os.environ["DEEPSEEK_API_KEY"],
temperature=0.7, # 控制生成随机性(0-1)
max_tokens=512 # 最大输出长度
)
# 创建对话提示模板
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个乐于助人的AI助手"),
("user", "{input}")
])
# 创建简单对话链
chain = prompt | model
# 执行对话
response = chain.invoke({
"input": "请用Python写一个快速排序算法,并解释其原理"
})
print("AI回复:\n", response.content)
另外一种选择是,最新的langchain库已经提供了deepseek的扩展库 langchain-deepseek
因此直接使用该库,也可以很方便的调用DeepSeek的API。
# 安装必要库(如果未安装)
# pip install -U langchain-deepseek
export DEEPSEEK_API_KEY="your-api-key"
from langchain_deepseek import ChatDeepSeek
llm = ChatDeepSeek(
model="deepseek-chat",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
# api_key="...",
# other params...
)
messages = [
("system", "You are a helpful translator. Translate the user sentence to French."),
("human", "I love programming."),
]
response = llm.invoke(messages)
print(response)
# Stream response
response = llm.stream(messages)
for chunk in response:
print(chunk)
使用LangChain Go调用DeepSeek的API
Golang 非常适合开发云原生后端应用,同时相比Python,Golang的性能更高,更适合开发高性能的应用。
LangchainGo is the Go Programming Language port/fork of LangChain.
以下提供一个使用LangchainGo调用DeepSeek的API的示例。
package main
import (
"context"
"fmt"
"log"
"github.com/tmc/langchaingo/llms"
"github.com/tmc/langchaingo/llms/openai"
)
func main() {
// Initialize the OpenAI client with Deepseek model
llm, err := openai.New(
openai.WithModel("deepseek-reasoner"),
)
if err != nil {
log.Fatal(err)
}
ctx := context.Background()
// Create messages for the chat
content := []llms.MessageContent{
llms.TextParts(llms.ChatMessageTypeSystem, "You are a helpful assistant that explains complex topics step by step"),
llms.TextParts(llms.ChatMessageTypeHuman, "Explain how quantum entanglement works and why it's important for quantum computing"),
}
// Generate content with streaming to see both reasoning and final answer in real-time
completion, err := llm.GenerateContent(
ctx,
content,
llms.WithMaxTokens(2000),
llms.WithTemperature(0.7),
llms.WithStreamingFunc(func(ctx context.Context, chunk []byte) error {
fmt.Print(string(chunk))
return nil
}),
)
if err != nil {
log.Fatal(err)
}
// Access the reasoning content and final answer separately
if len(completion.Choices) > 0 {
choice := completion.Choices[0]
fmt.Printf("\n\nReasoning Process:\n%s\n", choice.ReasoningContent)
fmt.Printf("\nFinal Answer:\n%s\n", choice.Content)
}
}
使用DeepSeek模型开发智能应用的场景
DeepSeek 模型和其他大模型一样,在多个领域具有广泛的应用:
- 城市治理:AI 可以处理公众请求,协助政府工作人员,并通过 AI 助手和公众关切问题的智能分析来支持决策制定。
- 客户服务:通过集成 DeepSeek API,企业可以创建 24/7 全天候可用的 AI 助手,用于回答客户问题并提高响应速度。
- 内容创作:DeepSeek 能够快速生成高质量的文本,例如新闻报道、博客文章和营销内容,提高内容创作效率。
- 教育:DeepSeek 可用于开发智能教育平台,根据学生的表现个性化学习计划,识别知识盲点,并提供针对性的练习。
- 医疗:DeepSeek 的智能诊断系统可以快速分析医学影像,提供精准的诊断建议,从而辅助诊断和药物研发。
- 金融:它可以分析金融数据,提供投资建议、风险评估以及欺诈预防。
DeepSeek 模型还可应用于智能家居,实现语音交互和场景识别;在智能交通领域,用于优化交通流量和辅助驾驶。
此外,DeepSeek 模型适用于需要高推理能力的任务,例如解决数学问题、编写代码以及处理逻辑复杂的场景。
DeepSeek V3 模型兼容 OpenAI API,具有高性价比和优异性能,能够降低获取、部署和使用大模型的成本,
加速其在商业和消费场景中的应用。
我个人的开发案例
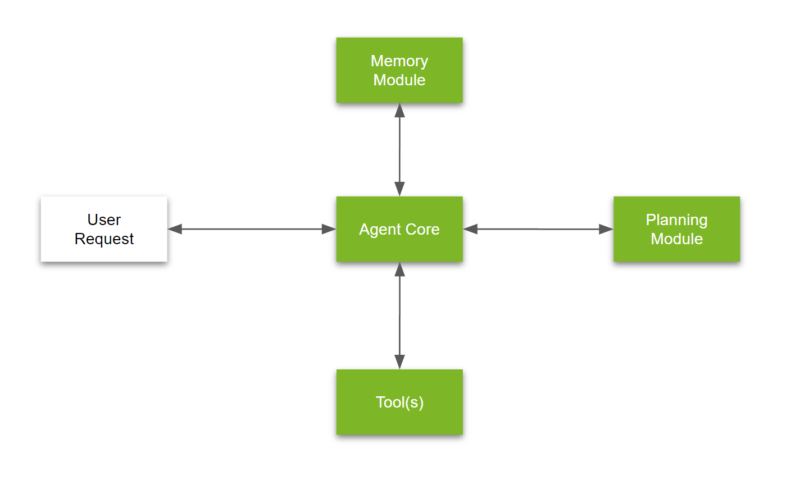
目前我正在探索使用AI大模型来提升Linux运维效率,以下是一些探索和实践。
基于DeepSeek 的 nuwa-terminal 智能终端助手
nuwa-terminal 是一个在终端中与大语言模型(LLM)聊天的程序,该工具基于LLM,旨在使终端更加智能。这个终端可以帮助用户使用自然语言 执行命令或任务,同时它还可以作为终端智能助手,你可以询问任何关于软件开发的任何问题。
该文章基于原生deepseek开发的智能终端工具nuwa-terminal 会有详细的介绍。
GitHub地址:nuwa-terminal
基于DeepSeek 的 Linux 系统监控程序
AI Agentic Monitor 是一个基于 AI 智能体技术的系统监控工具。它旨在监控Linux及Cloud系统的状态,并提供实时警报和系统优化建议。
它还非常智能,可以帮助您找到问题的根本原因并提供解决方案。目前该项目还在开发中,欢迎感兴趣的朋友一起参与。
GitHub地址:AI Agentic Monitor