最近随着大模型相关技术的演进和迭代,尤其是随着各种AI Agent的不断涌现,工程师们对AI工程技术又有了新的理解,于是“上下文工程”这个新的概念横空出世。
我非常喜欢上下文工程这个术语,它听起来更加系统和广泛,这让人以下就可以联想到,开发智能体或者知识助手时,提升AI输出质量所做的一切工作。
什么是上下文工程
那么什么是上下文工程呢?一开始我也非常好奇,但是随着我不断深入的了解,我发现它并不是完全新的技术,反而它包括的技术都是我所熟悉的,更加准确的说,“上下文工程” 是我们面向大模型开发服务时,所用的一系列技术的代名词,原来我们所用的一系列技术散落在各个角落,现在有了上下文工程的概念,这些技术被统一起来,同时有了统一的目标。
上下文工程(Context Engineering)是一个新兴的、至关重要的领域,尤其在大型语言模型(LLM)时代。它指的是系统性地设计、构建和优化输入给 AI 模型(特别是 LLM)的上下文(Context),以引导模型生成更准确、更相关、更符合预期的输出的一系列方法和实践。
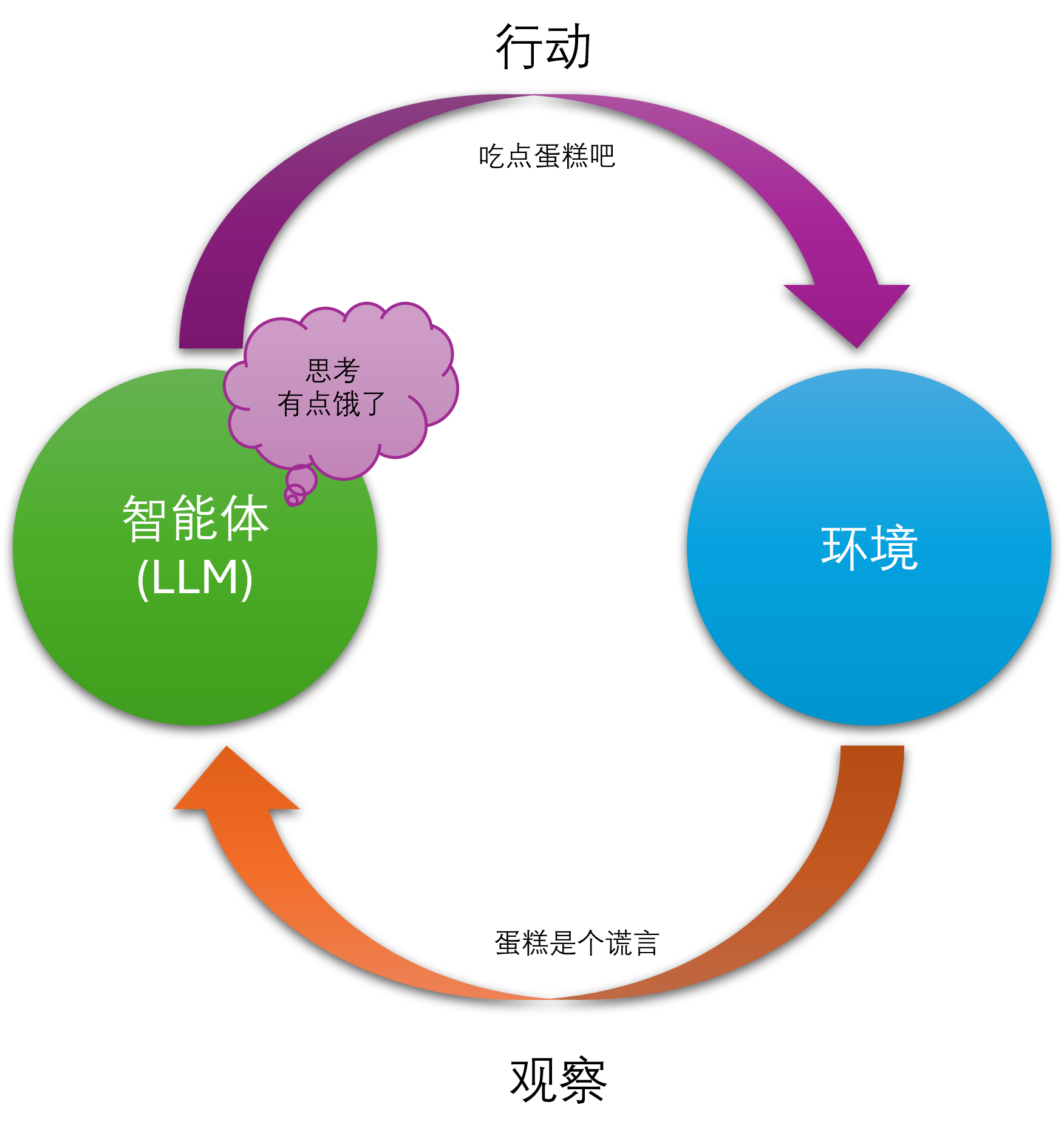
你可以将其理解为一种“AI 沟通的艺术与科学”。我们不是在修改模型本身(那属于模型训练或微调),而是在优化我们与模型“对话”的方式。这个“对话”的输入,就是我们所说的“上下文”。
一个简单的类比是:向一位知识渊-博但没有特定背景信息的专家提问。
糟糕的上下文: “给我写个关于车的故事。” (专家可能会写一个关于马车、F1赛车或者未来飞行汽车的故事,完全不符合你的预期)。
优秀的上下文(经过上下文工程): “你是一位专业的汽车杂志编辑,为一本面向家庭读者的杂志撰写一篇短文。请以一位父亲的视角,讲述他如何选择第一辆七座家用 SUV 的经历。文章需要突出安全性、空间和燃油经济性,风格要温馨、幽默。字数在800字左右。” (专家现在有了清晰的角色、目标受众、主题、关键点、风格和格式要求,能够写出非常贴切的内容)。
上下文工程的核心组成部分
上下文工程通常包含以下几个关键部分。

提示词工程(Prompt Engineering)
这是上下文工程最基础、最核心的部分。它专注于设计和优化直接输入给模型的指令文本(即“提示词”)。提示词工程包括了一系列相关提示词的技术:
- 明确指令(Clear Instruction): 清晰地告诉模型要做什么,避免模糊不清的词语。
- 角色扮演(Role-playing): 让模型扮演一个特定角色(如“你是一位资深律师…”)。
- 提供示例(Few-shot Learning): 给出几个输入和输出的范例,让模型学习并模仿。
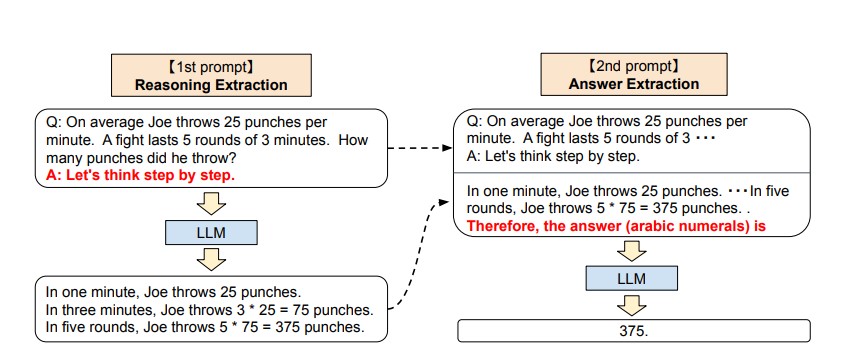
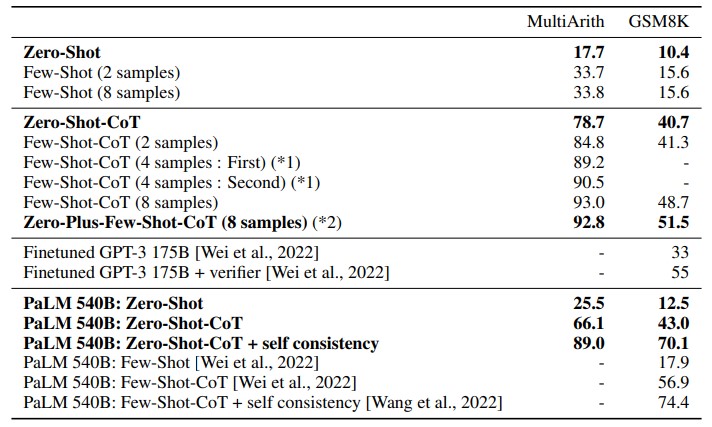
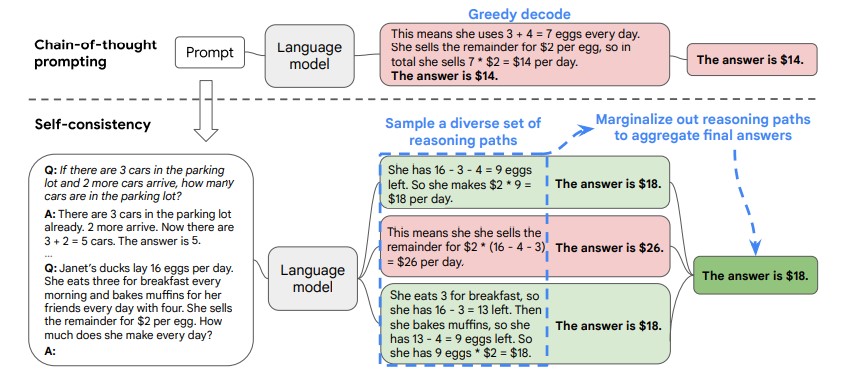
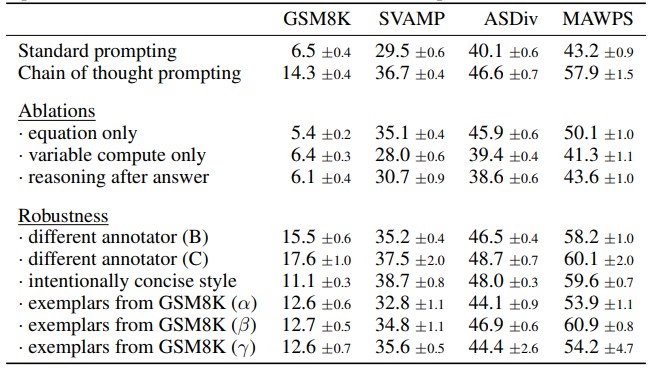
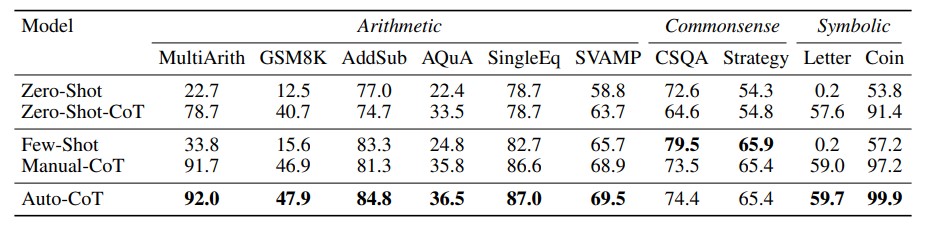
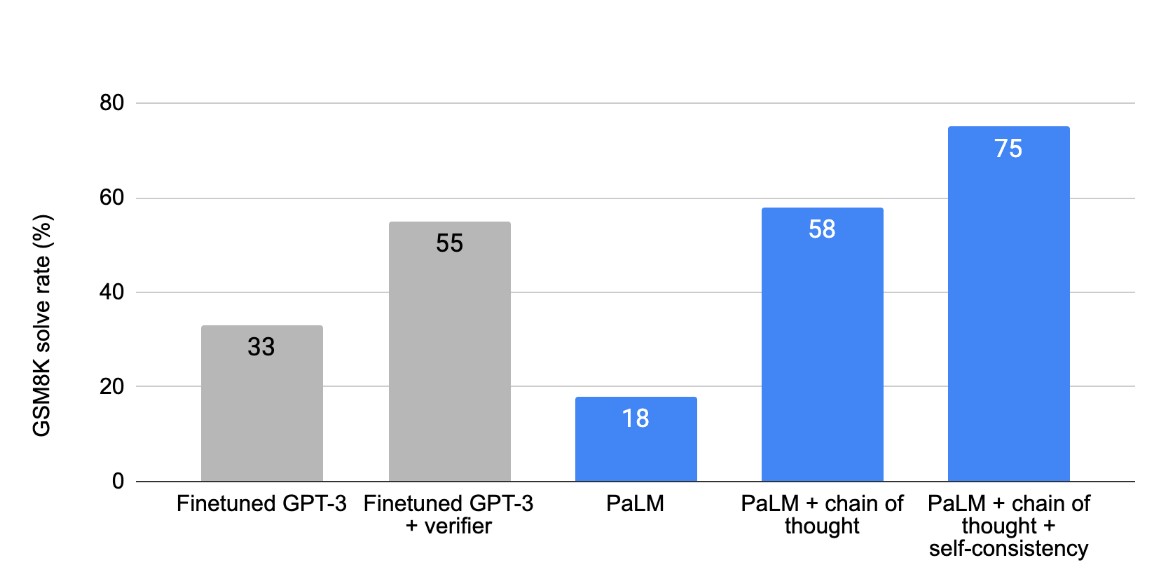
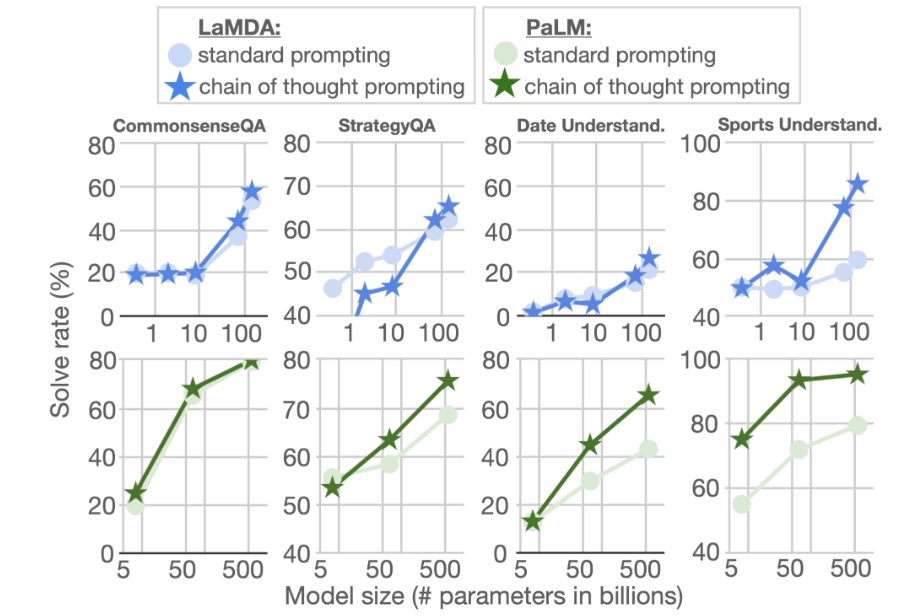
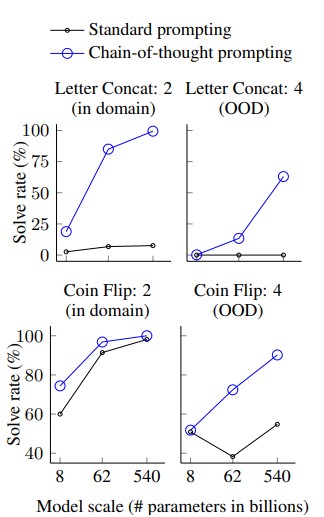
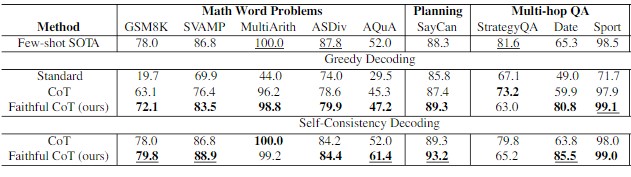
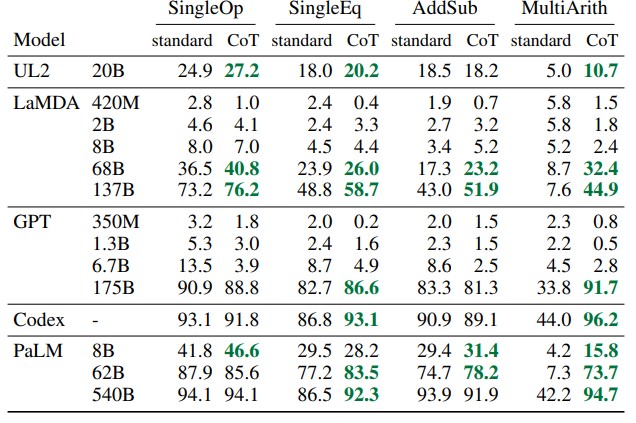
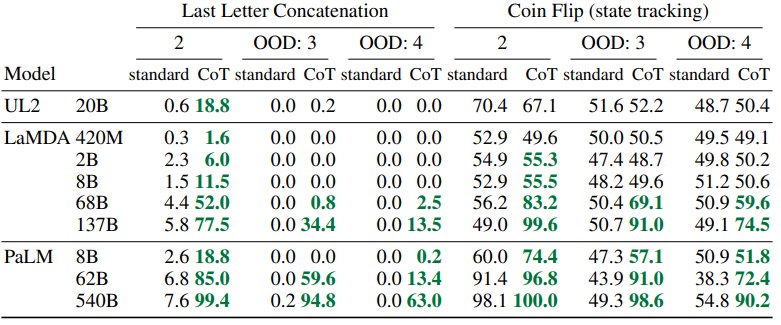
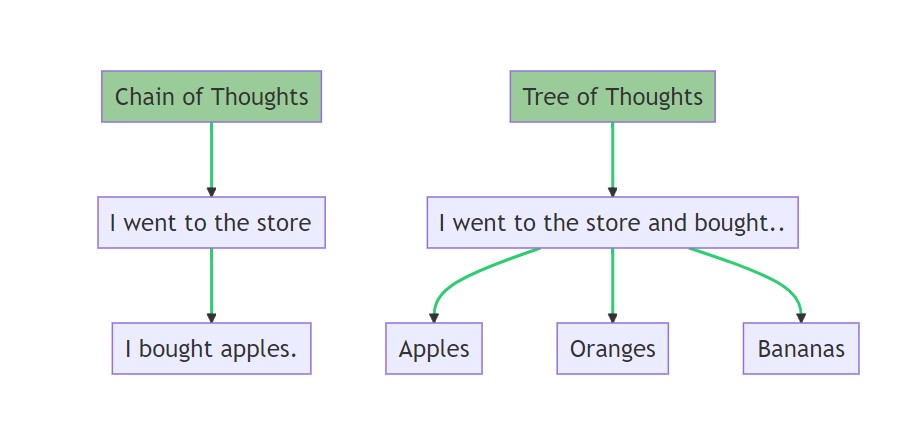
- 思维链(Chain-of-Thought, CoT): 引导模型一步一步地思考,将复杂问题分解,从而得出更可靠的结论。
设定输出格式(Format Specification): 要求模型以特定格式输出,如 JSON、Markdown 表格、HTML 等。
比如以下提示词是应用了提示词工程方法的案例,用来生成校验密码强度的函数:
# 角色
你是一位专注于网络安全的高级 Python 工程师。
# 任务
编写一个名为 validate_password_strength 的 Python 函数,该函数接收一个字符串作为密码,并返回一个包含两部分的 JSON 对象:
1. isValid (布尔值): 指示密码是否满足所有规则。
2. reasons (字符串列表): 如果 isValid 为 false,列出所有不满足的规则。
# 思维链 (Chain-of-Thought) 指导
在生成代码前,请先按以下步骤思考:
1. **定义规则:** 密码必须满足以下所有条件:
* 最小长度为 12 个字符。
* 至少包含一个大写字母。
* 至少包含一个小写字母。
* 至少包含一个数字。
* 至少包含一个特殊字符(例如 !@#$%^&*)。
2. **设计逻辑:** 创建一个 reasons 列表。逐条检查上述规则,若不满足,则将对应的失败原因(英文描述)添加到列表中。
3. **确定最终结果:** 如果 reasons 列表为空,则 isValid 为 true,否则为 false。
4. **构建 JSON 输出:** 根据 isValid 和 reasons 的最终值,构建并返回所需的 JSON 格式。
# 开始生成代码
检索增强生成(Retrieval-Augmented Generation, RAG)
当模型的内部知识不足(比如,对于最新的信息、私有领域的知识库或非常专业的内容)时,RAG 就显得尤为重要,它极大地减少了模型“胡说八道”(幻觉)的概率,提高了答案的准确性和时效性,并且可以引用信息来源。
- 检索(Retrieve): 当用户提出问题时,系统首先从一个外部的知识库(如公司的内部文档、数据库、网站等)中检索最相关的信息片段。
- 增强(Augment): 将检索到的这些信息片段,连同用户的原始问题,一起整合到提示词中。
- 生成(Generate): 将这个“增强后”的上下文发送给 LLM,让它基于这些最新、最相关的“外部知识”来生成答案。
此处通过一个示例来展示 RAG 的工作流程:
假设你的公司有一个自研的部署平台叫“Phoenix”,任何公开的 LLM 都不可能知道它的细节。
场景: 一位新员工问:“如何用 Phoenix 平台回滚一次部署?”
RAG 工作流:
查询(Query): 用户输入问题 “How to roll back a deployment with Phoenix?”。
检索(Retrieve):
系统首先将该问题通过 embedding 模型(如 text-embedding-ada-002)转换为一个向量。
然后,在存储了公司所有内部技术文档(Confluence, Wiki 等)的向量数据库(如 Pinecone, Chroma)中,执行相似性搜索。
搜索返回了最相关的几个文档片段,例如文档 "Phoenix CLI v2.1 Reference" 中的一段:“To initiate a rollback, use the command phoenix deployment rollback –deployment-id
–target-version . You can find the deployment ID using phoenix deployment list…” 增强(Augment): 系统动态构建一个新的、增强的上下文。
# 上下文信息
# 文档来源: Phoenix CLI v2.1 Reference
---
To initiate a rollback, use the command phoenix deployment rollback --deployment-id <ID> --target-version <VERSION>. You can find the deployment ID using phoenix deployment list.
---
# 用户问题
用户问:如何用 Phoenix 平台回滚一次部署?
# 指令
请仅基于以上提供的上下文信息,回答用户的问题。
- 生成(Generate): LLM 接收到这个增强的上下文,会生成一个精准、基于事实的回答:“要使用 Phoenix 平台回滚部署,你可以使用 phoenix deployment rollback 命令…”,而不是编造一个虚假的命令。
上下文构建与管理(Context Construction & Management)
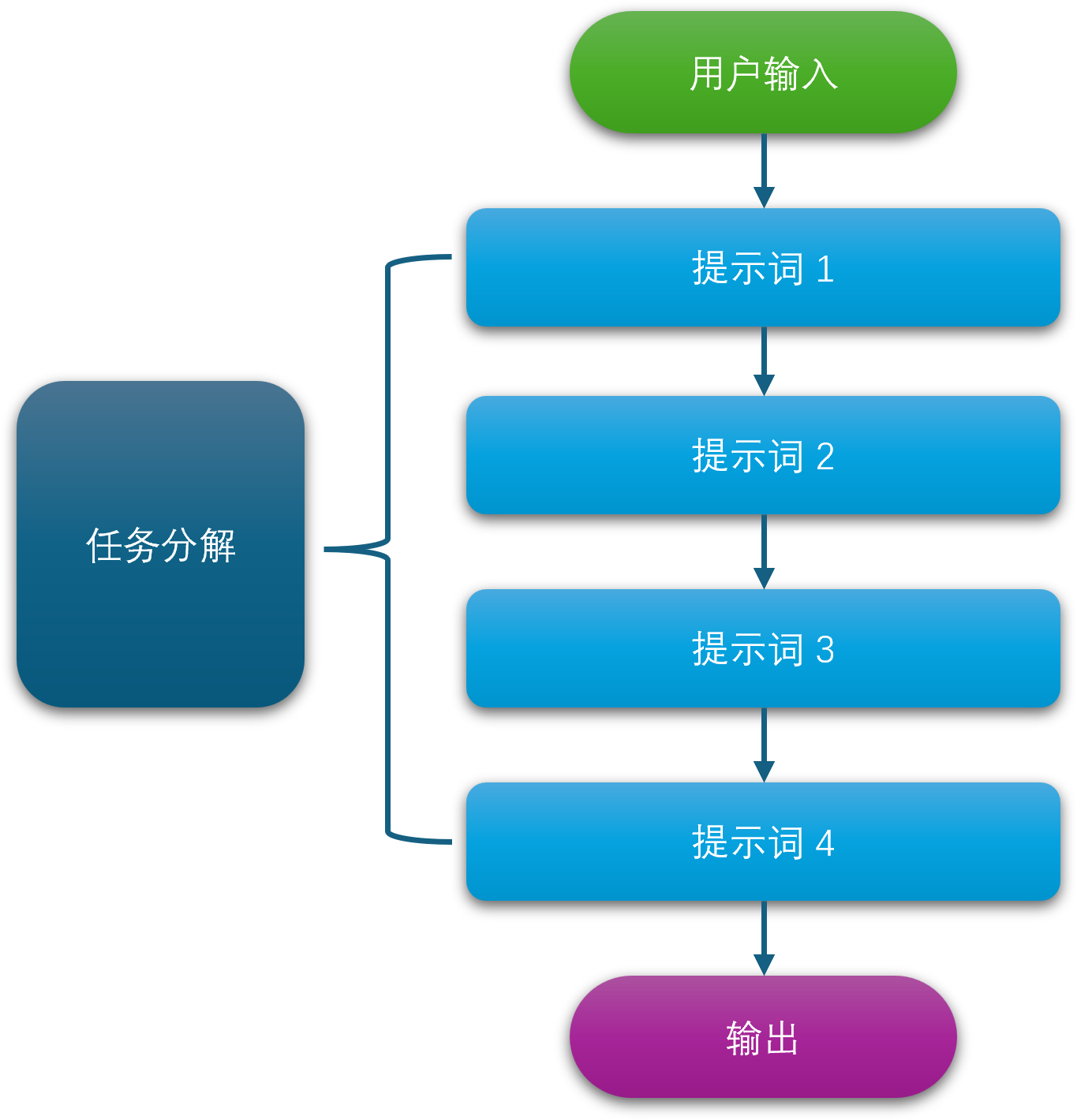
这部分关注的是如何动态地、智能地构建和维护整个上下文窗口(Context Window)。LLM 的输入长度是有限的(即上下文窗口),如何有效利用这个有限的空间至关重要。
- 上下文压缩(Context Compression): 在保持关键信息的同时,删减不重要或冗余的内容,以节省空间。
- 对话历史管理(Conversation History Management): 在多轮对话中,如何有效地总结和管理之前的对话历史,确保对话的连贯性,同时避免上下文窗口被陈旧信息占满。
- 动态上下文注入(Dynamic Context Injection): 根据对话的进展或用户的行为,实时地从外部源(如用户画像数据库、实时传感器数据等)拉取信息并注入到上下文中。
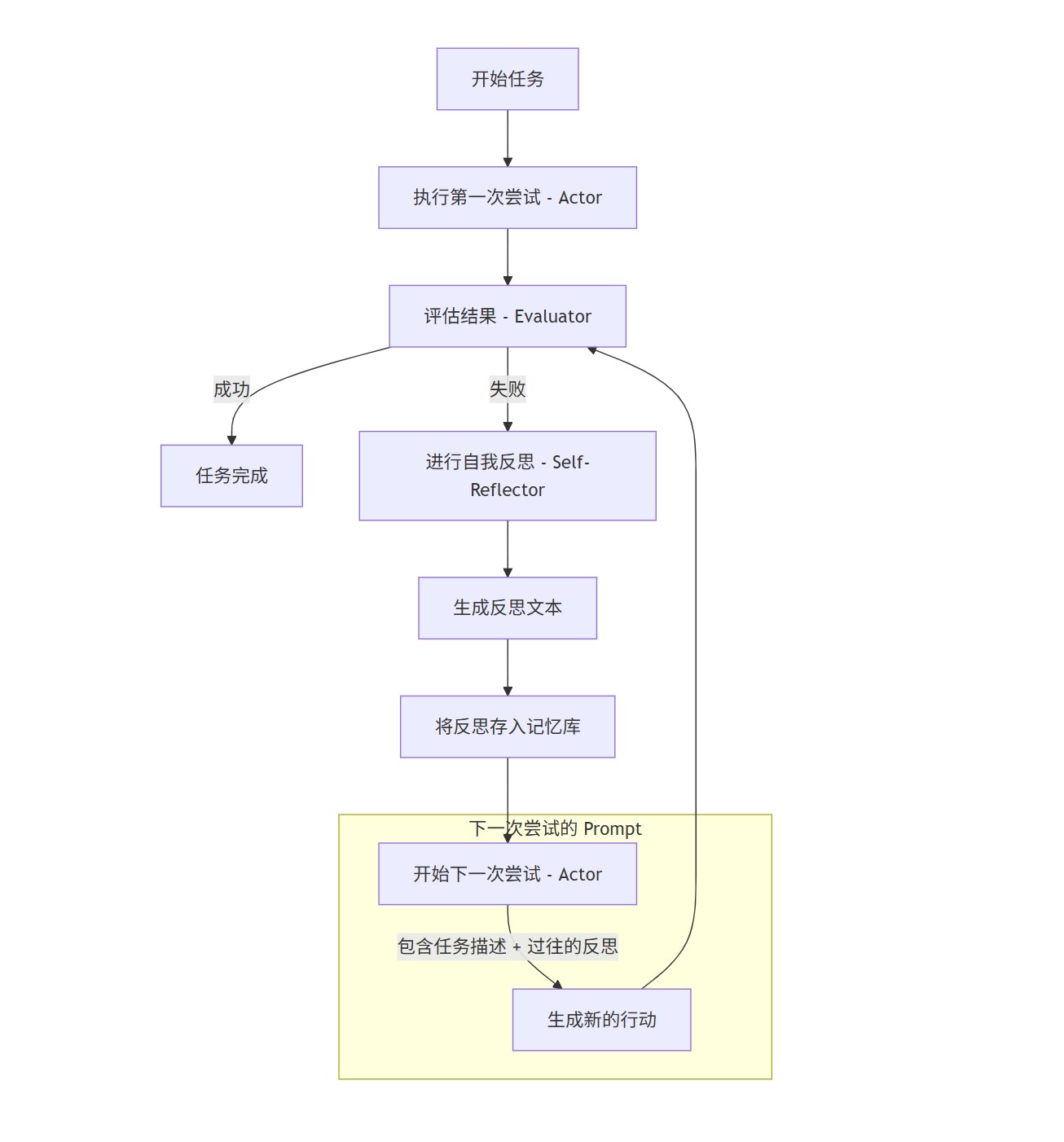
记忆机制(Memory Systems)
- 短期记忆:维护当前会话状态、任务链信息。
- 长期记忆:保存跨会话历史、用户偏好,通过检索机制注入上下文中
工具调用
在对话中根据任务需求调用外部接口/API,例如日历查询、数据库检索等,并将结果动态注入上下文。
提示词工程过时了么?
最近看到了一种观点,有了上下文工程,提示词工程将过时了。我可以肯定的回答,至少目前来看,这是一种完全错误的认知和引导,这种观点没有建立在对上下文工程的深入理解和认知上。
提示词工程不仅不会过时,它反而是上下文工程不可或缺的基石。
更准确地说,两者的关系是“包含与演进”,而非“替代与淘汰”。上下文工程是一个更宏大、更系统化的框架,而提示词工程是这个框架中至关重要的执行层。
我们可以用一个类比来理解:可以将两者的关系类比为 SQL 查询 与 数据库架构设计。
- 提示词工程 (Prompt Engineering) 就像是编写高效、精确的 SQL 查询。你需要懂得语法、技巧(如 JOIN, WHERE, GROUP BY),以从数据库中获取你想要的确切数据。这项技能永远不会过时,因为你总需要从数据库中拿数据。
- 上下文工程 (Context Engineering) 则像是 数据库架构设计。它关注的是整个数据系统的搭建,包括设计表结构、建立索引(类似 RAG 中的向量索引)、管理数据关系、进行性能优化等。一个好的架构能让你更容易写出高效的 SQL,并确保整个系统的稳定和可扩展。
你不可能只懂数据库架构而不懂如何写 SQL 查询。同理,一个完整的上下文工程策略,离不开底层的提示词工程技术。
为什么提示词工程不会过时,而是被整合和升级了呢?
它是与 LLM 交互的“原子操作”。无论你的系统多么复杂,在“最后一步”(The Last Mile),你总是需要将所有信息整合成一个最终的提示词(Prompt)发送给 LLM。这个最终提示词的质量,直接决定了输出的成败。
- 在 RAG 中: 当你从知识库检索到5个相关文档片段后,如何将这些片段、用户的原始问题、以及行为指令(例如:“请仅根据以上信息回答”、“总结要点”)高效地组合成一个能让 LLM 精准理解的最终提示词?这本身就是一项高级的提示词工程任务。一个糟糕的组合方式可能会让模型感到困惑,忽略掉关键信息。
- 在 Agent 应用中: 当一个 AI Agent 需要决定下一步使用哪个工具时,它背后往往是一个“元提示词”(Meta-Prompt)在引导它思考。这个元提示词的设计(例如,使用 ReAct 或其他思维链模式)是纯粹的提示词工程。
上下文工程的“组件”需要提示词来驱动。上下文工程的很多策略,本身就是由提示词来执行的。
- 对话历史摘要: 在管理上下文窗口时,一种常用策略是让 LLM 自身去“总结”之前的对话。那么,你用来指令 LLM 进行总结的那个请求——“请将以下对话总结为包含关键实体和用户意图的摘要”——就是一个需要精心设计的提示词。
- 数据提取与格式化: 当你希望 LLM 从一段非结构化文本中提取信息并以 JSON 格式输出时,你用来定义 JSON 结构、提供示例、下达指令的文本,同样是提示词工程的范畴。
技能的演进:从“手工作坊”到“系统化工程”。我们可以说,早期的“提示词工程”更像是一种经验性的、有点“炼丹”感觉的手工作坊模式。而“上下文工程”则是将这些成功的经验和模式, systematize(系统化)、industrialize(工业化),形成了一套更可靠、更具扩展性的工程方法论。
- 过去: 一个“提示词工程师”可能花大量时间在一个独立的 Playground 里调试一个完美的提示词。
- 现在与未来: 他的工作台变成了一个完整的系统。他不仅要设计单个提示词,还要思考这个提示词如何与外部知识库(RAG)、对话管理器、工具调用等其他系统模块协同工作。他的技能要求从“写好一句话”扩展到了“设计好整个对话流”。
上下文工程-面向AI的软件工程
传统的软件系统是通过程序员在键盘上飞舞的双手,一行行敲击来构筑的,为了构建稳定,可靠,强扩展的应用程序,架构师,软件工程师和测试工程师通力合作,他们应用了架构模式,设计模式,API设计规范,测试技术等一系列软件工程技术,来生产更加稳定可靠的系统。但是随着AI大模型的发展,我们正在见证着传统软件向智能化软件进化的历史进程,对于如何实现可靠的智能化软件系统,AI工程师们也在不断探索和实践。上下文工程正在基于这种可靠软件系统的诉求应用而生,这也成为一种历史必然。
通过上下文工程带来如下好处:
提升模型性能和准确性: 这是最直接的好处。好的上下文可以显著减少模型的错误和幻觉,让输出结果更贴近事实和用户需求。
降低成本和复杂性: 相比于重新训练(Re-training)或微调(Fine-tuning)一个庞大的语言模型,上下文工程的成本要低得多,实施起来也更快速、更灵活。它允许我们在不改变模型底层的情况下,适配各种不同的应用场景。
增强可控性和可解释性: 通过 RAG 等技术,我们可以知道模型是依据哪些信息来生成答案的,这增强了系统的透明度和可信度。同时,通过精心设计的提示词,我们可以更好地控制模型的输出风格、语气和内容。
实现个性化和动态适应: 上下文工程使得 AI 应用能够整合实时的、个性化的用户信息,提供千人千面的服务。例如,一个 AI 客服可以根据用户的历史购买记录(通过 RAG 检索得到)提供更有针对性的建议。
如果说大型语言模型是强大的“引擎”,那么上下文工程就是设计精良的“驾驶舱”和“导航系统”。它决定了我们如何驾驭这股强大的力量,将其引导到正确的方向,去完成具体、有价值的任务。