
Coze 如何自定义插件-获取公众号文章列表
关于Coze
毫无疑问,2023年是大模型元年,那么2024年,将会是LLM Agent应用爆发的一年。通过LLM agent 模式,AI 大模型将会释放自己的能力,助力更多的应用智能化。
Coze 平台是字节跳动开发的一款能够低代码创建AI agent的平台,无论你是否有编程经验,Coze 平台都能让你轻松创建各种聊天机器人,并将它们部署到不同的社交平台和消息应用中。该平台通过提供友好的界面和强大的功能,使得用户可以快速上手,开发出具有个性化和智能交互功能的机器人。简而言之,Coze 平台为聊天机器人的开发和应用提供了一个简单、高效、多功能的环境。
关于如何使用Coze,及了解更多的信息,可以阅读Coze 操作文档
本篇文章将主要聚焦于如何自定义Coze的工具(插件)。
创建Coze的插件
进入 Coze 主页
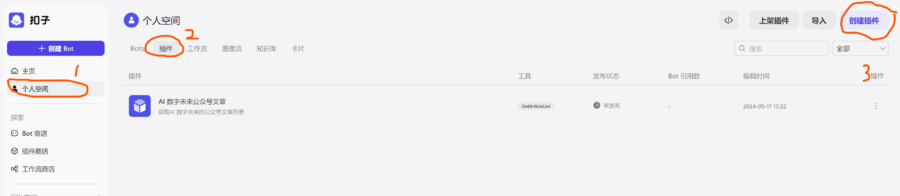
- 1 选择个人空间。
- 2 选择插件。
- 3 点击创建插件按钮,进入创建插件界面。
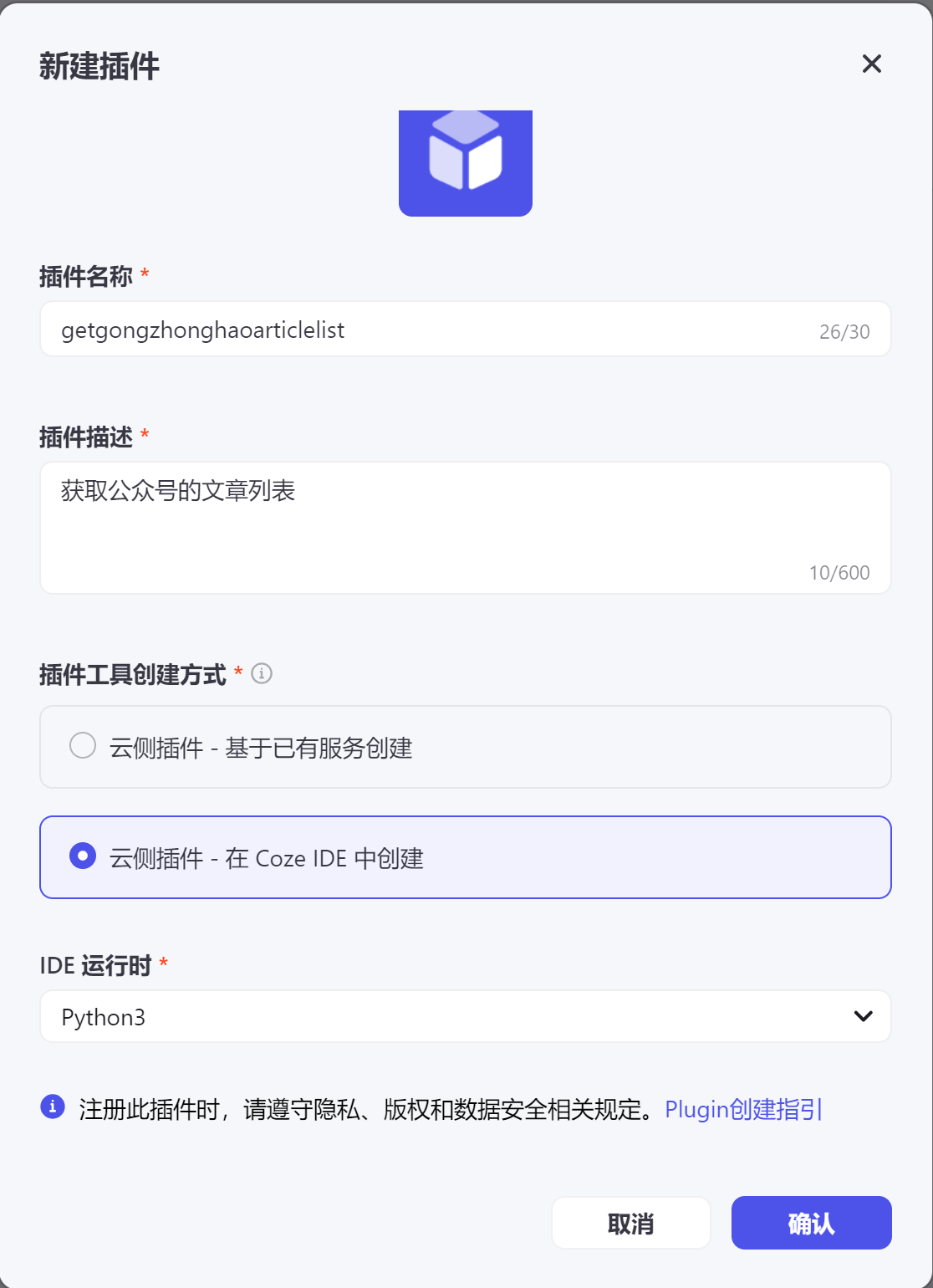
根据上图:
- 填写插件命名,可以使用中文。
- 填写插件描述,简单描述插件的用途。
- 选择在Coze IDE 中创建。
- 有两种编程语言可选,Node.js 和 Python3, 本实例使用python,因此选择Python3
- 点击 确认
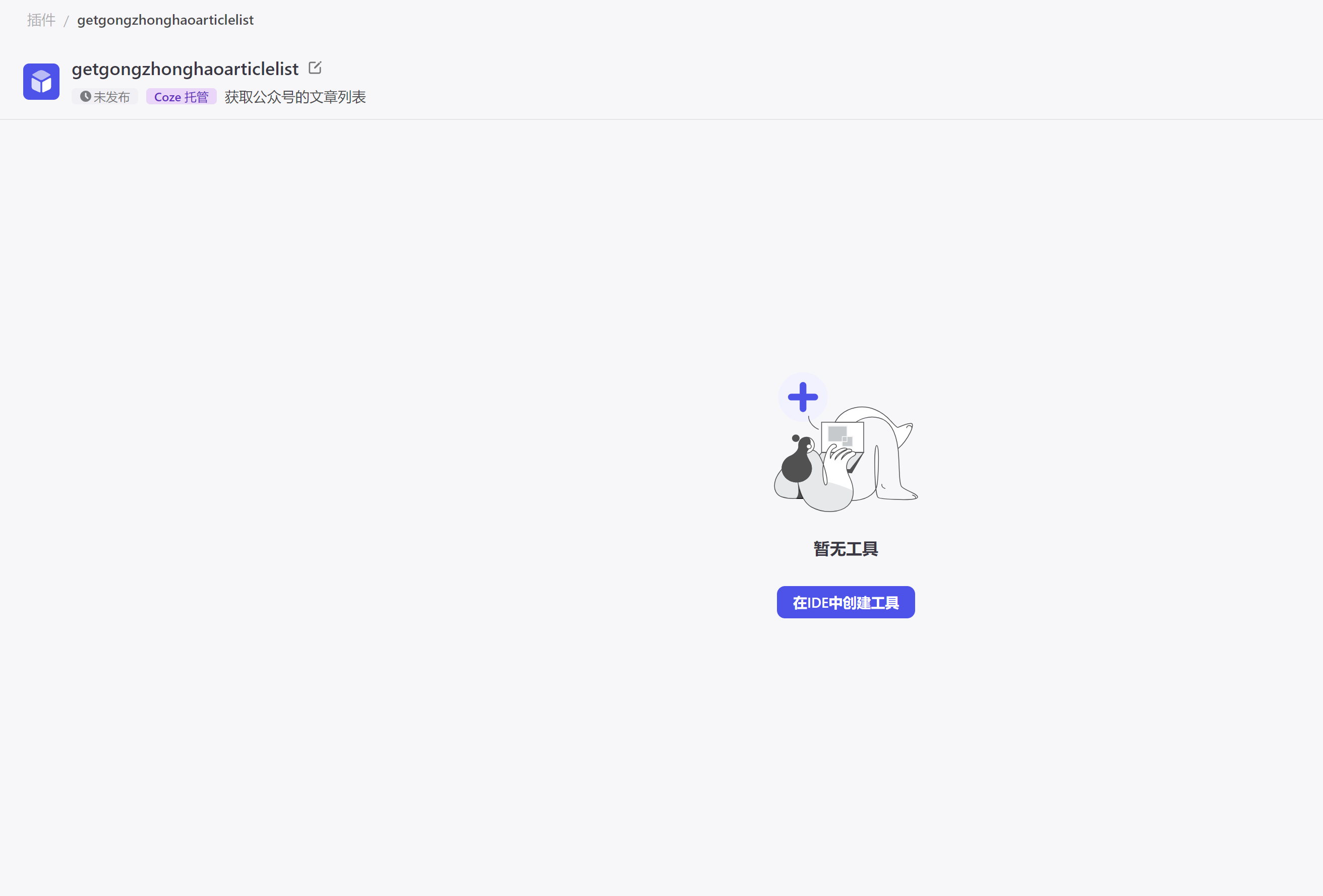
点击按钮 在IDE中创建工具
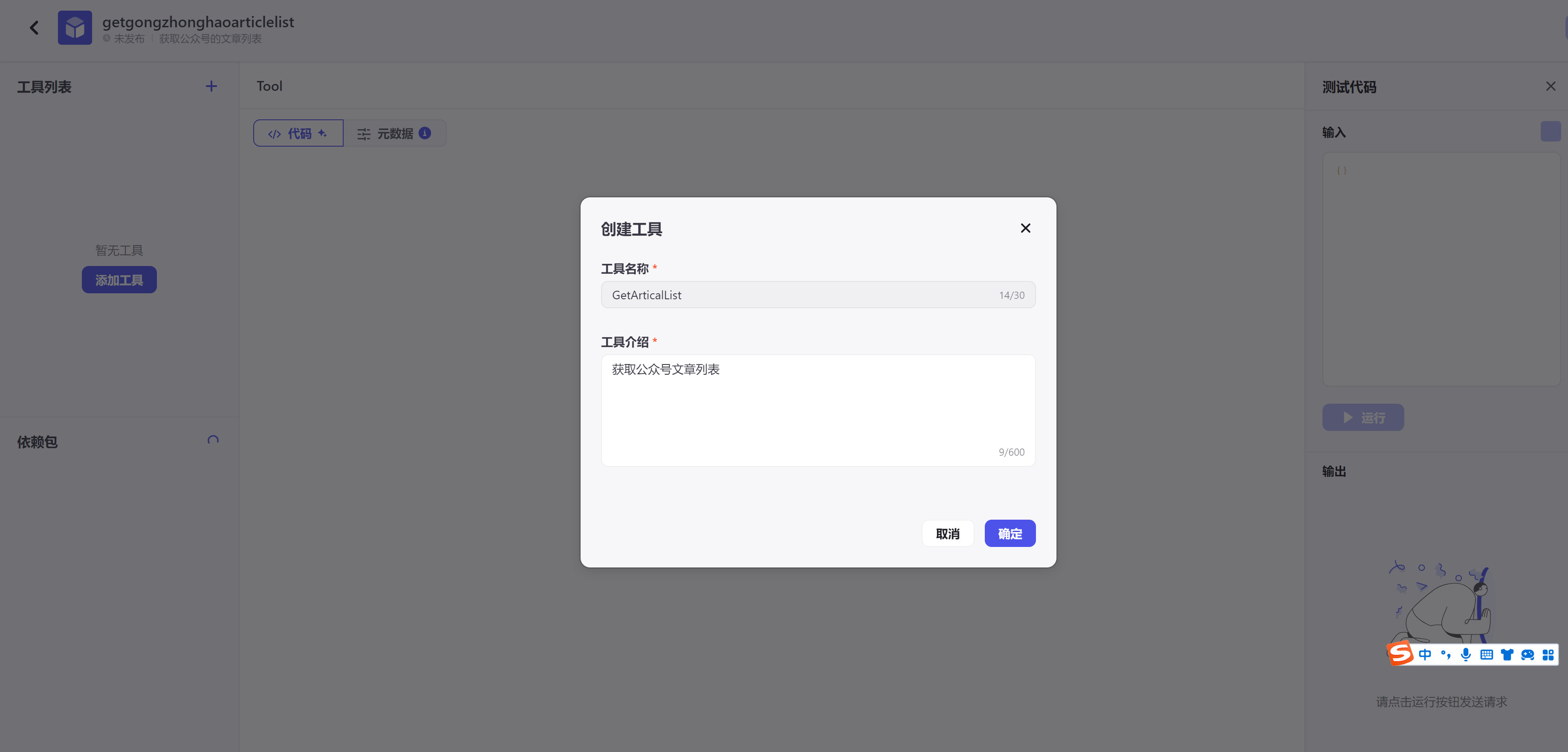
命名工具,必须以字母数字下划线格式命名,跟函数命名一致。
描写工具的用途。点击 确认。
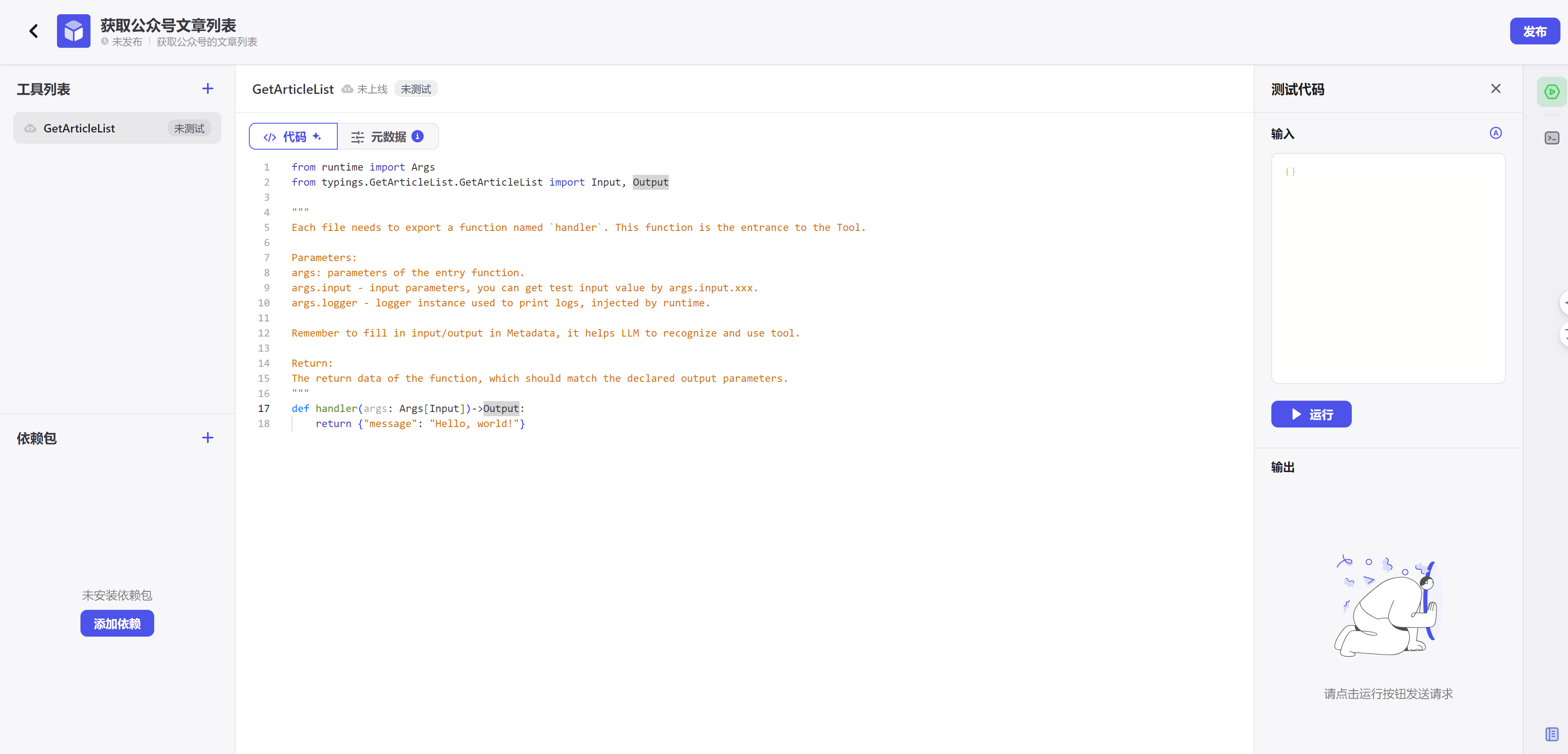
此时,你可以通过编程实现handler函数,来实现你的插件功能。
如果该工具需要自定义输入输出参数,则可通过元数据标签页,添加输入参数和输出参数。
分别使用输入参数和输出参数的编辑按钮,编辑输入参数和输出参数。
由于获取公众号文章时,公众号API需要使用公众号的appid和secret来获取访问资源的token,因此在此定义输入参数为appid和secret。
同时输出为公众号文章的列表,因此输出是一个数组,并且数组的每个item是一个对象,该对象具有如下字段:title,author,digest,url,如下图所示。
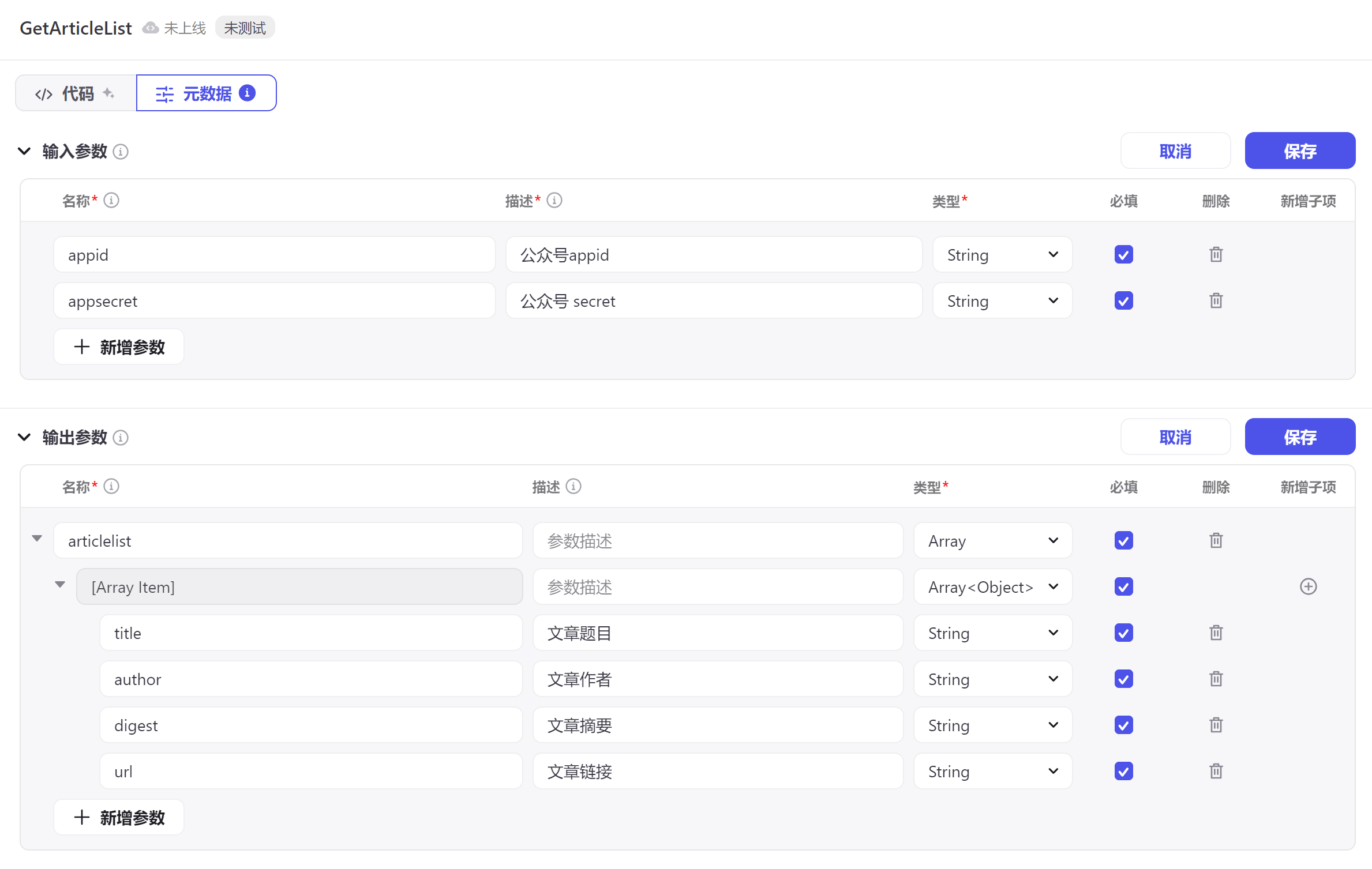
编辑完成后记得点击保存。然后切换到代码标签页。
由于公众号的API依赖于requests, 因此需要使用添加依赖,添加依赖的库。
添加依赖以后,就可以编程实现相应的功能,以下是获取公众号文章的代码。
from runtime import Args
from typings.GetArticleList.GetArticleList import Input, Output
import json
import requests
def get_stable_access_token(appid, secret, force_refresh=False):
"""
获取稳定的访问令牌
参数:
appid (str):微信小程序的 appid
secret (str):微信小程序的 secret
force_refresh (bool):是否强制刷新令牌,默认为 False
返回:
dict:访问令牌的 JSON 数据
"""
url = "https://api.weixin.qq.com/cgi-bin/stable_token"
payload = {
"grant_type": "client_credential",
"appid": appid,
"secret": secret,
"force_refresh": force_refresh
}
headers = {'Content-Type': 'application/json;charset=utf-8'}
response = requests.post(url, headers=headers, data=bytes(json.dumps(payload), encoding='utf-8'))
print(response)
if response.status_code == 200:
return response.json()
else:
response.raise_for_status()
def extract_info(articles):
"""
提取文章列表中所有文章的信息
Args:
articles (dict):包含文章列表的 JSON 数据
Returns:
list:包含所有文章信息的列表,每个元素是一个字典
"""
result = []
if "item" in articles:
for item in articles["item"]:
if "content" in item and "news_item" in item["content"]:
for news_item in item["content"]["news_item"]:
# 获取文章的标题、作者、摘要和 URL,如果没有则为空字符串
title = news_item.get("title", "")
author = news_item.get("author", "")
digest = news_item.get("digest", "")
url = news_item.get("url", "")
# 创建一个新的 JSON 对象来存储提取的信息
article = {
"title": title,
"author": author,
"digest": digest,
"url": url
}
result.append(article)
return result
def get_published_articles(access_token, offset, count, no_content):
"""
获取已发布的文章列表
参数:
access_token (str):调用接口的 access_token
offset (int):要获取的文章列表的起始位置
count (int):要获取的文章数量
no_content (bool):是否返回文章内容
返回:
str:返回的文章列表的 JSON 字符串
"""
url = f"https://api.weixin.qq.com/cgi-bin/freepublish/batchget?access_token={access_token}"
payload = {
"offset": offset,
"count": count,
"no_content": no_content
}
headers = {'Content-Type': 'application/json;charset=utf-8'}
response = requests.post(url, headers=headers, data=json.dumps(payload))
text = response.content.decode('utf-8')
if response.status_code == 200:
return text
else:
response.raise_for_status()
"""
Each file needs to export a function named <code>handler</code>. This function is the entrance to the Tool.
Parameters:
args: parameters of the entry function.
args.input - input parameters, you can get test input value by args.input.xxx.
args.logger - logger instance used to print logs, injected by runtime.
Remember to fill in input/output in Metadata, it helps LLM to recognize and use tool.
Return:
The return data of the function, which should match the declared output parameters.
"""
def handler(args: Args[Input])->Output:
offset = 0
count = 100
no_content = 0
appid = args.input.appid
appsecret = args.input.appsecret
access_token = get_stable_access_token(appid, appsecret)
token = access_token['access_token']
content = get_published_articles(token, offset, count, no_content)
articles = json.loads(content)
result = extract_info(articles)
return result
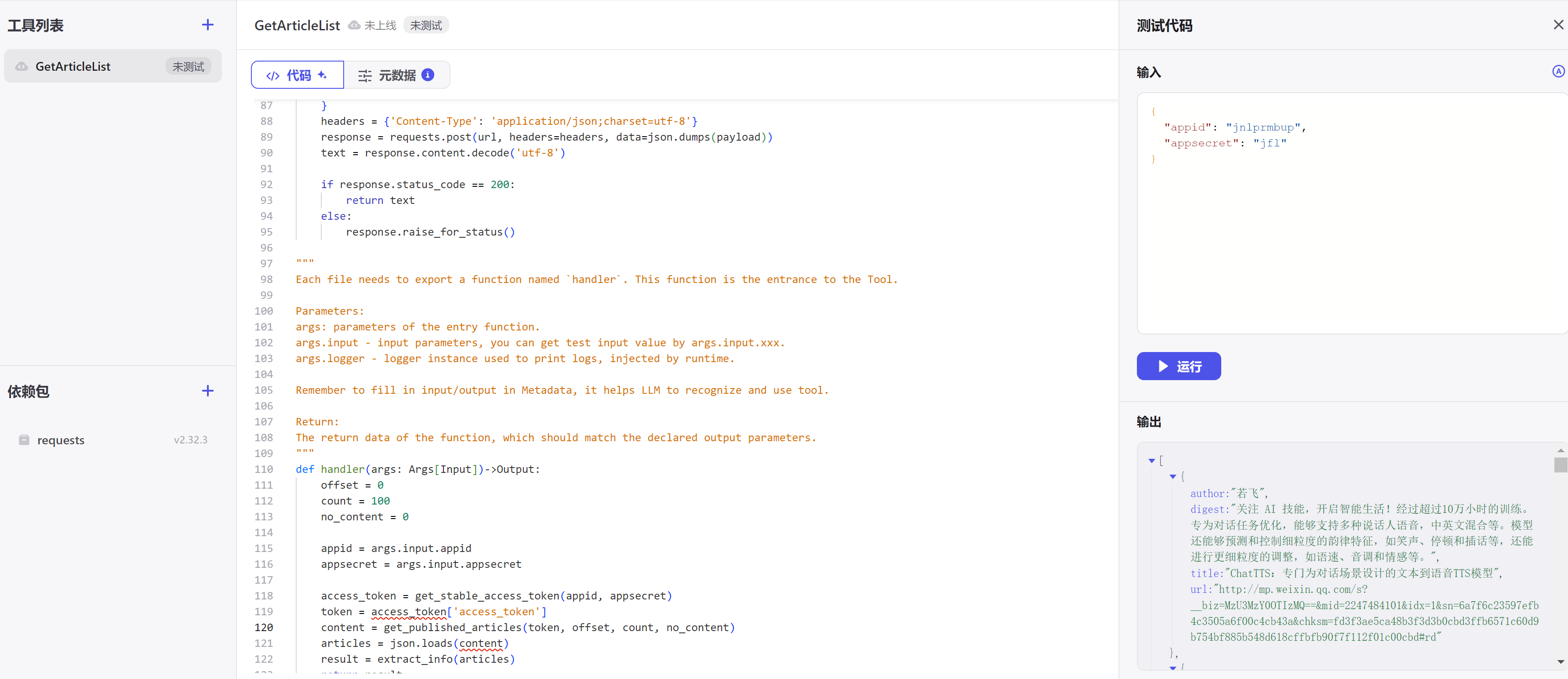
运行测试时,输入以下参数,运行可以查看结果。
{
"appid":"your appid",
"appsecret":"your appsecret"
}
测试通过即可将你的插件进行发布。